
Dans cet article on va comprendre les bases de la création d'une interface utilisateur à l'aide de Glade3 (User interface Designer) et PyGi (PyGObject).
Ce tutoriel traitera un exemple simple et basique et se sera centré sur l'appel des méthodes de PyGi et la manière de lier un fichier XML généré par Glade3 et notre code en PyGi.
Assez parler! Débutons ... !
Création d'une fenêtre de type Top Level nommée (son id) Window1:

Modifier l'affichage de la fenêtre et la forcer à apparaître au centre de l'écran:

Modifier le titre de la fenêtre:

Modifier les dimensions de la fenêtre par défaut:

Utiliser Grid comme Container (La liste des container est regroupée sur Glade, mais dans cet exemple on va utiliser uniquement Grid avec une dimension 3x3 nommé Grid1):

La fenêtre sera divisée comme suit:

Notre Grid sera ajouté automatiquement à l'hiérarchie de Window1 :

Dans Grid1 on ajoute ces Widgets listés dans le champs Control and display de Glade3. On aura une interface similaire à cella:
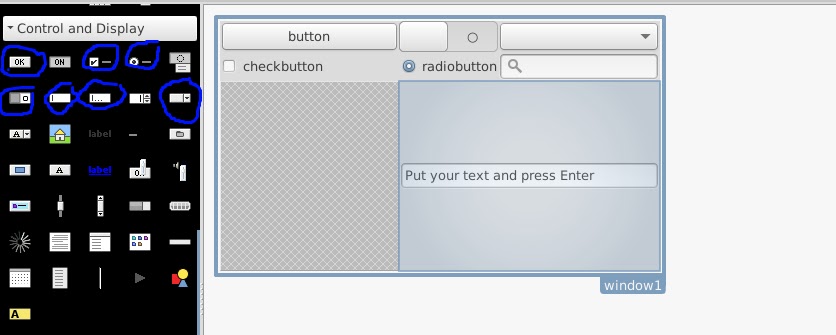
La liste des éléments et leur types ajoutés à Window1 s'affichent comme suit:

On modifie les propriétés de button1 (bouton ajouté à Windows1). On modifie le nom qui s'affiche sur le bouton et on le renomme Sortir :

On ajoute un signal (événement) à button1 de type clicked et on lie le signal à la méthode on_button :

On ajoute un signal (événement) à comboboxtext1 de type changed et on lie le signal à la méthode on_comboboxtext :

On ajoute le signal (événement) à checkbutton1 de type toggled et on lie le signal à la méthode on_toggle :

On ajoute le signal (événement) à entry1 de type activate et on lie le signal à la méthode on_entry_activate:

On ajoute le signal (événement) au searchentry1 et de type activate et on lie le signal à la méthode on_entry_activate:

Le logiciel s'affichera comme suit:

Pour le widget checkbutton1 on va le faire manuellement en modifiant le fichier XML généré par Glade. On va ajouter le signal au child switch1 (qui signifie que switch1 est l'enfant de Window1) comme ceci:
<signal name="notify::active" handler="on_switch_activate" swapped="no"/>
Cette ligne se traduit avec PyGi en:
switch1.connect("notify::active", on_switch_activate)
Ceci dit lier switch1 à un signal de type notify::active (notification active)
Sans beaucoup étaler le tutoriel, voilà le fichier XML généré par Glade3 et le code source en PyGi avec des commentaires pour comprendre l'utilisation et le fonctionnement de chaque ligne.
Code source du fichier XML de Glade3:
<!-- Exemple mis en ligne par: Chiheb NeXus Licence : Aucune licence! Langage de programmation: XML généré par Glade3 --> <?xml version="1.0" encoding="UTF-8"?> <!-- Generated with glade 3.16.1 --> <interface> <requires lib="gtk+" version="3.10"/> <object class="GtkWindow" id="window1"> <property name="can_focus">False</property> <property name="title" translatable="yes">Test Glade3 & PyGi (Python3)</property> <property name="window_position">center-always</property> <property name="default_width">500</property> <property name="default_height">250</property> <child> <object class="GtkGrid" id="grid1"> <property name="visible">True</property> <property name="can_focus">False</property> <child> <object class="GtkButton" id="button1"> <property name="label" translatable="yes">Sortir</property> <property name="visible">True</property> <property name="can_focus">True</property> <property name="receives_default">True</property> <property name="image_position">top</property> <signal name="clicked" handler="on_button" swapped="no"/> </object> <packing> <property name="left_attach">0</property> <property name="top_attach">0</property> <property name="width">1</property> <property name="height">1</property> </packing> </child> <child> <object class="GtkSwitch" id="switch1"> <property name="visible">True</property> <property name="can_focus">True</property> <!-- Ajout de l'appel du signal dans l'XML généré par Glade3 manuellement et lier le widget switch1 à un signal de type notify::active qui va pointer sur la méthode on_switch_activate --> <signal name="notify::active" handler="on_switch_activate" swapped="no"/> </object> <packing> <property name="left_attach">1</property> <property name="top_attach">0</property> <property name="width">1</property> <property name="height">1</property> </packing> </child> <child> <object class="GtkComboBoxText" id="comboboxtext1"> <property name="visible">True</property> <property name="can_focus">False</property> <property name="button_sensitivity">on</property> <items> <item translatable="yes">NeXus</item> <item translatable="yes">Nymph</item> <item translatable="yes">Tristiana</item> <item translatable="yes">Auroroe</item> <item translatable="yes">Liturgy</item> </items> <signal name="changed" handler="on_comboboxtext" swapped="no"/> </object> <packing> <property name="left_attach">2</property> <property name="top_attach">0</property> <property name="width">1</property> <property name="height">1</property> </packing> </child> <child> <object class="GtkCheckButton" id="checkbutton1"> <property name="label" translatable="yes">checkbutton</property> <property name="visible">True</property> <property name="can_focus">True</property> <property name="receives_default">False</property> <property name="xalign">0</property> <property name="draw_indicator">True</property> <signal name="toggled" handler="on_toggle" swapped="no"/> </object> <packing> <property name="left_attach">0</property> <property name="top_attach">1</property> <property name="width">1</property> <property name="height">1</property> </packing> </child> <child> <object class="GtkRadioButton" id="radiobutton1"> <property name="label" translatable="yes">radiobutton</property> <property name="visible">True</property> <property name="can_focus">True</property> <property name="receives_default">False</property> <property name="xalign">0</property> <property name="active">True</property> <property name="draw_indicator">True</property> </object> <packing> <property name="left_attach">1</property> <property name="top_attach">1</property> <property name="width">1</property> <property name="height">1</property> </packing> </child> <child> <object class="GtkEntry" id="entry1"> <property name="visible">True</property> <property name="can_focus">True</property> <property name="text" translatable="yes">Put your text and press Enter</property> <signal name="activate" handler="on_entry_activate" swapped="no"/> </object> <packing> <property name="left_attach">1</property> <property name="top_attach">2</property> <property name="width">2</property> <property name="height">1</property> </packing> </child> <child> <object class="GtkSearchEntry" id="searchentry1"> <property name="visible">True</property> <property name="can_focus">True</property> <property name="primary_icon_name">edit-find-symbolic</property> <property name="primary_icon_activatable">False</property> <property name="primary_icon_sensitive">False</property> <signal name="activate" handler="on_entry_activate" swapped="no"/> </object> <packing> <property name="left_attach">2</property> <property name="top_attach">1</property> <property name="width">1</property> <property name="height">1</property> </packing> </child> <child> <placeholder/> </child> </object> </child> </object> </interface>
Code source en PyGi de l'exemple:
#!/user/bin/python
# -*- coding: utf-8 -*-
###################################################################
# Exemple mis en ligne par: Chiheb NeXus
# Licence : Aucune licence!
# Langage de programmation: Python3 et PyGi (PyGtk Version 3)
###################################################################
from gi.repository import Gtk
class Handler():
"""
- Mettre tous les signaux dans une seule classe
- NB: Dans PyGi les argements des méthodes sont des widgets intermédiaires qui héritent toutes les caractéristiques
des widgets d'origine. Ceci dit, si on essaye de donner une action à un widget de type "button" nommé "button1"
dans la partie du code on écrit: def action(self, intermerdiare):
intermerdiare hérite toutes les caractéristiques de button1 et l'action sur intermerdiare est une action indirecte sur button1
Ceci est peut être bien expliqué en C/GTK+ vu que PyGi est en quelques sorte un porjet réecrit depuis C/GTK+.
- Ps: Lors d'une utilisation avancée de PyGi, les signaux jouent un rôle primordial dans la création de notre Gui.
C'est pourquoi une maîtrise de l'utilisation des signaux est fortement récommendée et, aussi, la modification du ficher XML
généré par Glade3 est, aussi, récommendée.
- Dans cet exemple, notre programme principale n'est pas mis dans une classe à part, vu sa simplicité. Mais, dans un programme
avancé, une bonne maîtrise de Python et de PyGi est nécessaire.
Glade3 ne permet que réduire le temps de création de Gui et éviter la création de l'interface à la main.
Cependant, ceci ne veut pas dire qu'on va oublier les manipulations manuelles pour parvenir aux résultas voulus.
- Documentation sur Github:
1- Toutes les méthodes Gtk.methodes (exemple: Gtk.main_quit())
https://lazka.github.io/pgi-docs/#Gtk-3.0/functions.html
2- Les méthodes supportées par Gtk.Button() {Comment interéagir avec les widgets de type Gtk.Button()}
https://lazka.github.io/pgi-docs/#Gtk-3.0/classes/Button.html#Gtk.Button
3- Les méthodes supportées par Gtk.Entry() {Comment interéagir avec les widgets de type Gtk.Entry()}
https://lazka.github.io/pgi-docs/#Gtk-3.0/classes/Entry.html#Gtk.Entry
4- Les méthodes supportées par Gtk.Switch() {Comment interéagir avec les widgets de type Gtk.Switch()}
https://lazka.github.io/pgi-docs/#Gtk-3.0/classes/Switch.html#Gtk.Switch
5- Les méthodes supportées par Gtk.ComboBoxText() {Comment interéagir avec les widgets de type Gtk.ComboBoxText()}
https://lazka.github.io/pgi-docs/#Gtk-3.0/classes/ComboBoxText.html#Gtk.ComboBoxText
6- Les méthodes supportées par Gtk.ToggleButton() {Comment interéagir avec les widgets de type Gtk.ToggleButton()}
https://lazka.github.io/pgi-docs/#Gtk-3.0/classes/ToggleButton.html#Gtk.ToggleButton
7- Les méthodes supportées par Gtk.SearchEntry() {Comment interéagir avec les widgets de type Gtk.SearchEntry()}
https://lazka.github.io/pgi-docs/#RB-3.0/classes/SearchEntry.html#RB.SearchEntry
- Pour plus d'informations: https://lazka.github.io/pgi-docs/
"""
def on_button(self, button):
"""
- Gtk.main_quit(): Est une fonction par défaut de PyGi
qui permet de sortir de la boucle infinie de l'interface en Gtk+ en utilisant Python
- La méthode utilise le mot "self" et "button" comme arguments
- "button" joue le rôle d'un widget intermédiaire entre button1 et cette partie de code
"""
Gtk.main_quit()
def on_switch_activate(self, switch, args):
"""
- "switch" est un widget intermédiaire entre "switch1" et cette partie de code
et args est l'argument passé à la méthode lors de l'appel de widget "switch1"
- switch.get_active() : Cette méthode retourne "True" ou "False"
=> "True" = Le bouton (widget) est actif / "False" = Le bouton (widget) est inactif
"""
if switch.get_active():
# Bouton actif
print("Switch activé!")
else:
# L'inverse
print("Switch désactivé!")
def on_comboboxtext(self, combobox):
"""
- L'ajout des éléments à ComboBoxText est faite sous Glade3
- Cette méthode affichera uniquement les noms stockés dans le fichier XML générée par Glade3
- combobox.get_active_text() : Retourne le text activé de widget ComboBoxText lors de la saisie dans l'interface UI
Le type de retour est une chaine de caractaire (String) et l'affiche sera sous la terminale
"""
# On vérifie si combobox est vide ou non.
# S'il est vide, il n'y aura aucun affichage sinon on affiche le contenu
if combobox.get_active_text() != None:
print("L'élément saisi est: " + combobox.get_active_text())
def on_toggle(self, toggle):
"""
- Le bouton "toggle1" affiche sur la terminale "Toggle button est activé!" ou "Toggle button est désactivé"
- toggle.get_active() : Retourne "True" ou "False" et qui permet de vérifier l'état de widget (activé ou non)
- L'affiche est sous la terminale
"""
if toggle.get_active():
print("Toggle button est activé!")
else:
print("Toggle button est désactivé")
def on_entry_activate(self, entry):
"""
- Affichage du text saisi dans "entry1" et "seachentry1"
- entry est un widget intermédiaire entre "entry1" et "seachentry1"
- entry.get_text(): Retourne le text entré dans "entry1" et "seachentry1"
- L'affiche sera sur la terminale
"""
txt = entry.get_text()
print(txt)
#builder est de type Gtk.Builder() : Notre constructeur du fichier XML de Glade
builder = Gtk.Builder()
# Ajouter le chemin de fichier d'interface générée par Glade
builder.add_from_file("test.glade")
# Tous les signaus sont mis dans une classe nommée Handler()
builder.connect_signals(Handler())
# window est un objet qui hérite toutes les méthodes de window1
window = builder.get_object("window1")
# Affichage de la fenêtre window = Affichage de la fenêtre window1
window.show_all()
# Lier la fenêtre principale à un signal de destruction de la fenêtre
window.connect("delete-event",Gtk.main_quit)
# Lancer la boucle infinie qui permettera de visualiser l'interface indéfiniment sauf s'il y aura une intervention
# de l'utilisateur ou du programme interne
Gtk.main()
Code source: GladePyGi































